This is the second part in a series of posts exploring how to integrate Machine Learning functionalities into data catalogs. You might want to check the first part in which we introduce what embeddings are:
Part 1: Introducing Machine Learning Embeddings
In this post I’ll explain how I integrated embeddings into a CKAN extension to provide useful features for users. I’ve been working on this GitHub repository, which you are of course free to extend and use as a starting point but note that this is in no way ready for production:
https://github.com/amercader/ckanext-embeddings
In this post:
- The features
- Computing the embeddings
- Storing the embeddings
- Integrating with CKAN
- Using it
- What next?
The features
We will compute embeddings for all datasets in the CKAN instance using their metadata. As we saw on the previous post, this will allow us to compare these embeddings and build features that increase discoverability of relevant data for users. We’ll focus on these two initial features:
1. Similar datasets
By computing all datasets embeddings and rank them against a particular dataset one, we can get the most similar datasets to the one provided according to the model. This similarity won’t just take text-based similarity into account but also but the meaning and context of the dataset metadata. So for instance when looking for similar datasets to a “Bathing Water Quality” one, besides other datasets explicitly mentioning “water quality” in their metadata you’ll get others that might include things like “Wastewater Treatment”, “Aquaculture Sites” or “Lakes”.
We will implement a new API action that will return the X closest datasets to the one for the provided id, and create a small snippet to display these datasets in the UI.
2. Semantic search
Following the same approach as above, we can rank the embeddings of the portal datasets not against another dataset but against an arbitrary query term. That will give us the most similar datasets to the provided search term, and again we will get results semantically similar to the input query term, even if they don’t contain the query terms in their metadata.
Ideally we want to integrate this search with the standard CKAN one, so we can combine it with the usual filters, sorting options etc.
Computing the embeddings
The first step is clear, we need to compute the embeddings for all datasets in our database and store them somewhere so they can be compared.
Regardless of the actual source, from an architecture point of view we have two options, running a model locally or using an external API. In the first case you would use a library like SentenceTransformers that provide helpers and pre-trained models that you can download and run locally:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
inputs = [
"Operational Work of Fire Brigades 2016",
"Burren National Park Boundary Map"
]
embeddings = model.encode(inputs)
Alternatively you can just an API like the ones offered by OpenAPI or Google’s Vertex AI or call an API on one of your own models hosted in a platform like HuggingFace):
from openai import OpenAI
client = OpenAI(api_key=API_KEY)
inputs = [
"Operational Work of Fire Brigades 2016",
"Burren National Park Boundary Map"
]
response = client.embeddings.create(
input=inputs, model="text-embedding-ada-002"
)
embeddings = [v.embedding for v in response.data]
Both have pros and cons, and choosing one or the other would depend on each site’s architecture and requirements. Running the model locally is faster and gives you full control, and also avoids sending sensitive data to an external party if you have private datasets, but of course adds complexity to your deployment. There are costs associated with external commercial APIs although these tend to be quite low.
In any case, as this is likely to be something that each CKAN site might want to customize, the best is to provide a simple backends mechanism where users can create their own backend that uses their relevant model or API. (The two basic examples above using SentenceTransformers and OpenAI are provided by default).
Storing the embeddings
Once we have the embeddings computed (lists of numbers called vectors) we need to store them somewhere. There are many available vector databases but it would be nice to use one of CKAN existing requirements to not add more complexity.
Luckily both Postgres and Solr have good options to store vector fields. pgvector is an excellent Postgres extension that adds a Vector type to store vectors efficiently and all the built-in methods to perform similarity searches (like the cosine distance we used in Part 1. The Python package allows to use it with SQLAlchemy models, so you can integrate it with your existing models.
So assuming you stored the computed embeddings of each dataset with its id in a table, to get the 5 closest datasets to a specific one you would do something like:
class DatasetEmbedding(toolkit.BaseModel):
__tablename__ = "embeddings"
package_id = Column(
types.UnicodeText, ForeignKey(model.Package.id), primary_key=True
)
updated = Column(types.DateTime, default=datetime.utcnow)
embedding = Column("embedding", Vector(384))
model.Session.query(DatasetEmbedding, model.Package.title)
.join(model.Package)
.filter(DatasetEmbedding.package_id != dataset_id)
.order_by(
DatasetEmbedding.embedding.cosine_distance(dataset_embedding[0].embedding)
)
.limit(5)
.all()
On the other hand, Solr also supports indexing and storing embeddings, using the Dense Vector Search functionality. You need to add a new field type and field to your Solr schema, tailored to the dimensions that your embedding model uses:
<fieldType name="knn_vector" class="solr.DenseVectorField" vectorDimension="384" similarityFunction="cosine"/>
<field name="vector" type="knn_vector" indexed="true" stored="true"/>
It’s really easy to extend the official CKAN Solr Docker images to incorporate these fields (or to add multiple ones to test different models):
FROM ckan/ckan-solr:2.10-solr9
# Add the vector field type definition(s) and field(s)
# The default provided is meant to be used with Sentence Transformers' all-MiniLM-L6-v2 model
# For other models you will have to adjust the vectorDimension value
USER root
ENV SOLR_VECTOR_FIELD_DEFINITION '<fieldType name="knn_vector" class="solr.DenseVectorField" vectorDimension="384" similarityFunction="cosine"/>'
ENV SOLR_VECTOR_FIELD '<field name="vector" type="knn_vector" indexed="true" stored="true"/>'
RUN sed -i "/<types>/a $SOLR_VECTOR_FIELD_DEFINITION" $SOLR_SCHEMA_FILE
RUN sed -i "/<fields>/a $SOLR_VECTOR_FIELD" $SOLR_SCHEMA_FILE
USER solr
Integrating with CKAN
My first approach was to create a separate command that created the embeddings and stored them in the database using pgvector. I then created an action that run the SQLAlchemy query shown in the previous section to return the closest N datasets to the one provided.
This worked great for the Similar Datasets feature but to implement Semantic
Search, we have to index the embedding in Solr anyway so to simplify this first
iteration of ckanext-embeddings (which again, is just a proof of concept) I
dropped pgvector and the embeddings table entirely and just computed the
embedding every time we are indexing a dataset (in the before_dataset_index
plugin hook).
This has the benefit of not having to worry about the embeddings being up to date if you for instance update a dataset title, but it’s very likely not performant enough, certainly when calling an external API because the hooks are called on each individual dataset, so we can’t submit data in bulk.
A probably better option would be to have the embeddings cached in the database,
being created beforehand in the after_dataset_create and
after_dataset_update hooks. We might not even need pgvector, just store them
as arrays of floats or even strings, which is what we actually send to Solr.
Once the embeddings are indexed, it’s just a matter of constructing the right
query
in the before_dataset_search hook.
The whole thing is about 50 lines of code, you can check both hooks in the
plugin.py
file of the extension.
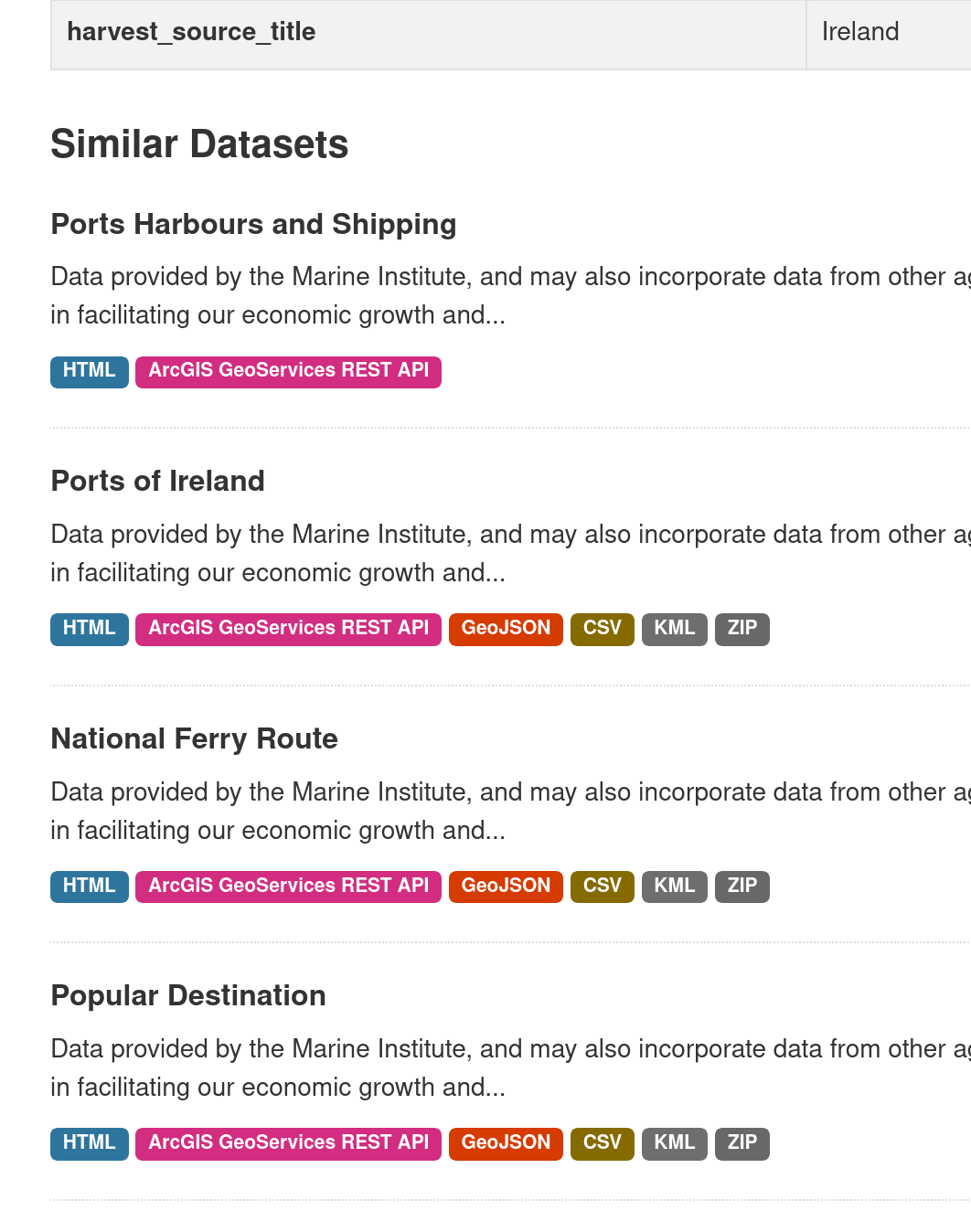
Using it
The plugin adds a package_similar_show action that will return the closest
datasets to the one provided with the id parameter (id or name). A template
helper is provided to integrate this in the UI, for instance adding the 5
closest datasets to the bottom of the dataset page:
Additionally, with the plugin activated, you can pass an extra parameter to the
package_search action to perform a semantic search instead of the default Solr
one.
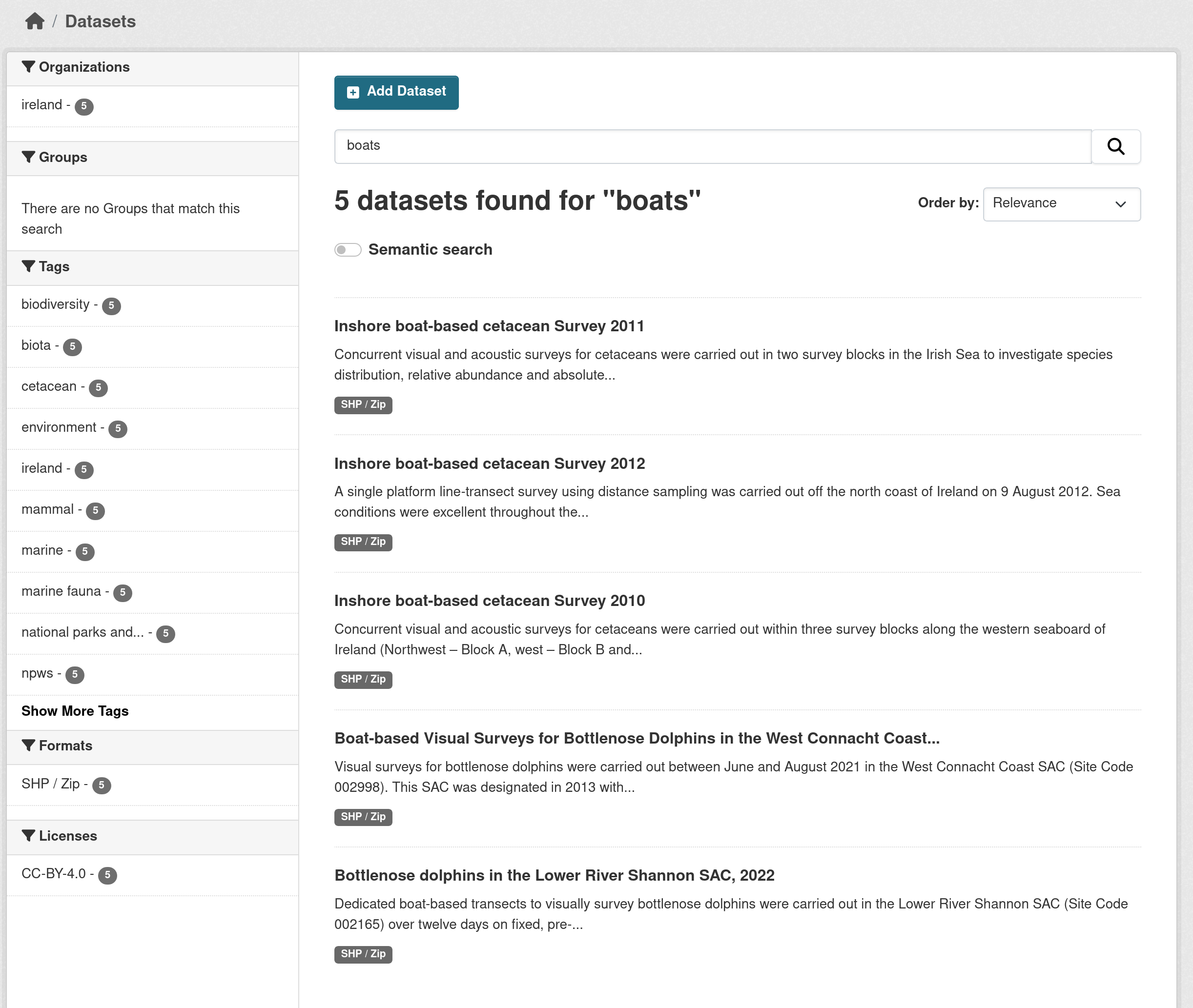
Consider the following standard search calls from the command line:
ckanapi action package_search q=boats | jq ".results[].title"
"Inshore boat-based cetacean Survey 2011"
"Inshore boat-based cetacean Survey 2012"
"Inshore boat-based cetacean Survey 2010"
"Boat-based Visual Surveys for Bottlenose Dolphins in the West Connacht Coast SAC in 2021"
"Bottlenose dolphins in the Lower River Shannon SAC, 2022"
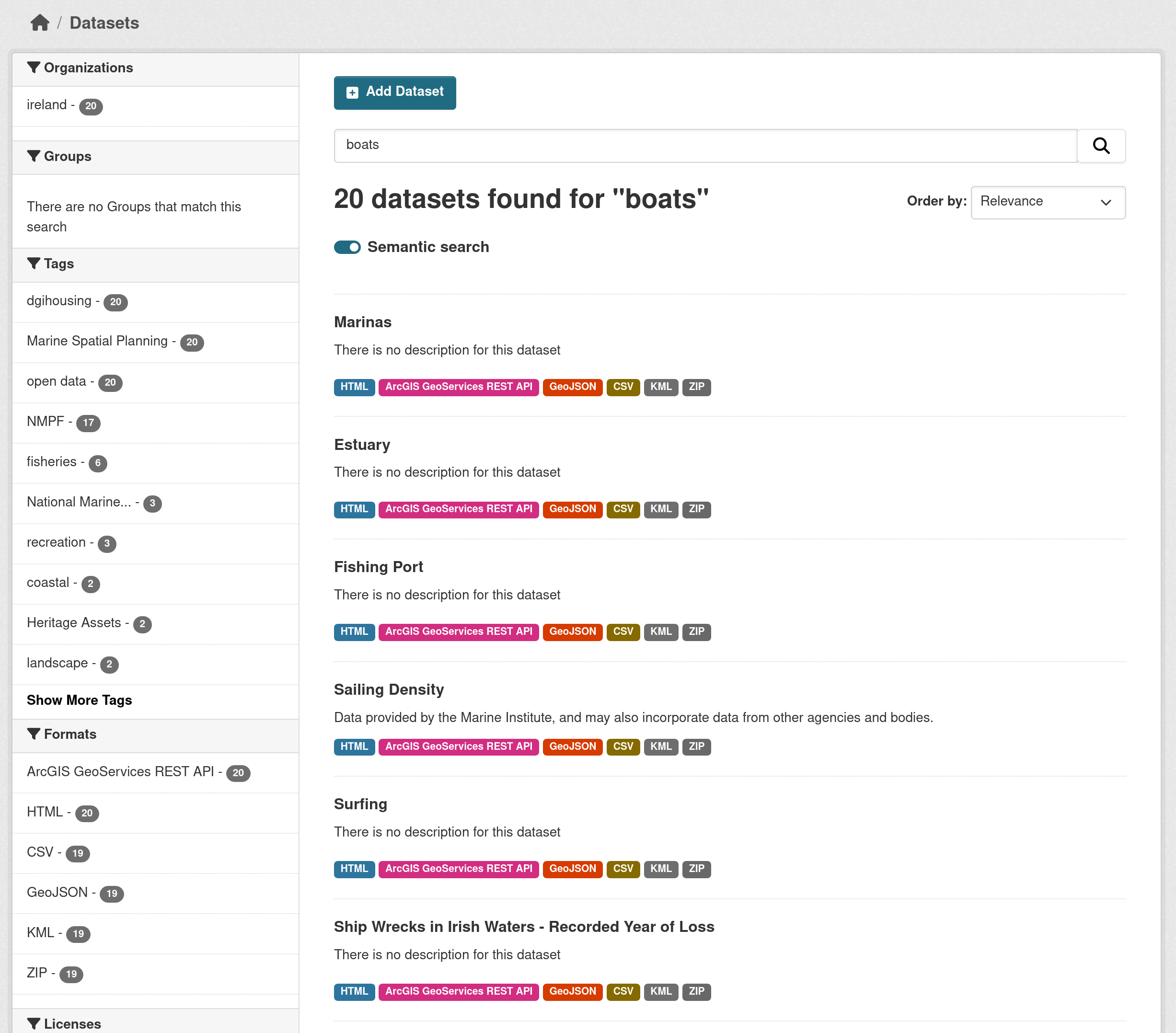
And this time using the semantic search:
ckanapi action package_search q=boats extras='{"ext_vector_search":"true"}' | jq ".results[].title"
"Marinas"
"Estuary"
"Fishing Port"
"Sailing Density"
"Surfing"
"Ship Wrecks in Irish Waters - Recorded Year of Loss"
"Sea Cliff"
"Seascape Coastal Type"
"Midwater Trawl FIshing"
"Net Fishing"
There’s one important distinction with the standard Solr search though, and that is that the Semantic search always returns a fixed number of results, regardless of relevance.
The standard search UI hasn’t been modified to account for this fact, but it probably should.
What next?
As it is now, the extension provides a good proof of concept, and the results seems to be promising, so it might be worth exploring further work to make it production ready. I only worked on it to learn more about embeddings and ML in general, so there is no actual roadmap or commitment to work on it on my side, but if I had to list what should be the focus next I’d say this:
- Training your own model: general purpose trained models seem to give decent results but maybe we can increase drastically the results quality by training a model with the actual metadata on the CKAN site (or across many multiple CKAN sites). I need to read and learn more about this and think on how to make easier to train models based on existing metadata.
- Improving performance caching the embeddings: as previously discussed, more thoughts on this issue.
- Better UI for the Semantic Search: rather than “X results returned” it’s more “X closest datasets to the query term”
But what this extension definitely needs is more testing on real data. So if you are interested and want to test it in your own instance please give it a go and let me know your findings.